Building persistent memory for my coding agents

I know, I'm late to the party but refining an building it to a phase where it actually matters, took some time.
GitHub: atharvavdeo/agent-mem
PyPI: easy-agent-mem
Every day, the same scene played out - Open VS/Claude/Cursor, Paste the same context I'd already pasted yesterday. Watch the agent confidently propose a refactor that contradicts a decision I made three sessions ago. If not, then waste tokens just making it understand the code.
A the time of the idea of solving this problem - I did not know of the existence of tools like mem0, let alone graphify. Ok, back to the main thing.
If you've shipped anything non-trivial with an AI coding agent, you know the loop. The model is brilliant for thirty messages and then the context window fills up, the session ends, and you're back to square one : re-explaining the architecture, re-listing the decisions, re-pasting the file tree. The agent has no memory. Worse, it pretends to but ends up eating tokens like kids on a birthday bash.
This post is about what I did about it. The tool is called agent-mem. It's a CLI-first persistent memory system for AI coding sessions. You can pip install easy-agent-mem it right now. But as much as I want to talk about the tool, more about the wall I kept running into, and how three unrelated ideas from Cursor, Karpathy, and Obsidian - ended up shaping the design.
Three things I stole
I didn't invent any of this. I stitched together three insights that had been floating in my head for days.
Cursor's structural parsing. Cursor doesn't grep your code. It runs it through tree-sitter and builds a real syntax tree, then indexes that tree. The reason Cursor's autocomplete feels different from a regex-based plugin is because it actually understands class Foo extends Bar as a class declaration with a parent, not as a string of characters that happens to contain the word "extends." That's the bar. Anything less is search dressed up as understanding.
Why it matters: if your "memory" system is just storing chat transcripts, it's a chat log with extra steps. Code memory has to know what a function is.
Our college's Operating System's lecture on RAM vs disk framing. Even Andrej said something offhand in a talk that I keep coming back to: an LLM's context window is RAM. Fast, expensive, volatile. Persistent memory has to live somewhere else - on disk, structured, addressable. You don't shove your entire hard drive into RAM at boot. You page in what you need. Not to mention his post on LLM-Wikis that blew up : Read it here.
Obsidian's local-first approach. Obsidian stores your notes as plain markdown files in a folder you own. No cloud. No lock-in. Wikilinks like [[some-note]] form a graph automatically. Open the folder in any text editor and it still works.
Why it matters: developers do not want their codebase memory living in someone else's database. We already have a vault - it's called the project directory. So, Use it!
Three different directions, one obvious synthesis: parse the code structurally (Cursor), persist the parsed signal as markdown (Obsidian), and treat that markdown as the disk layer the agent pages from (Karpathy).
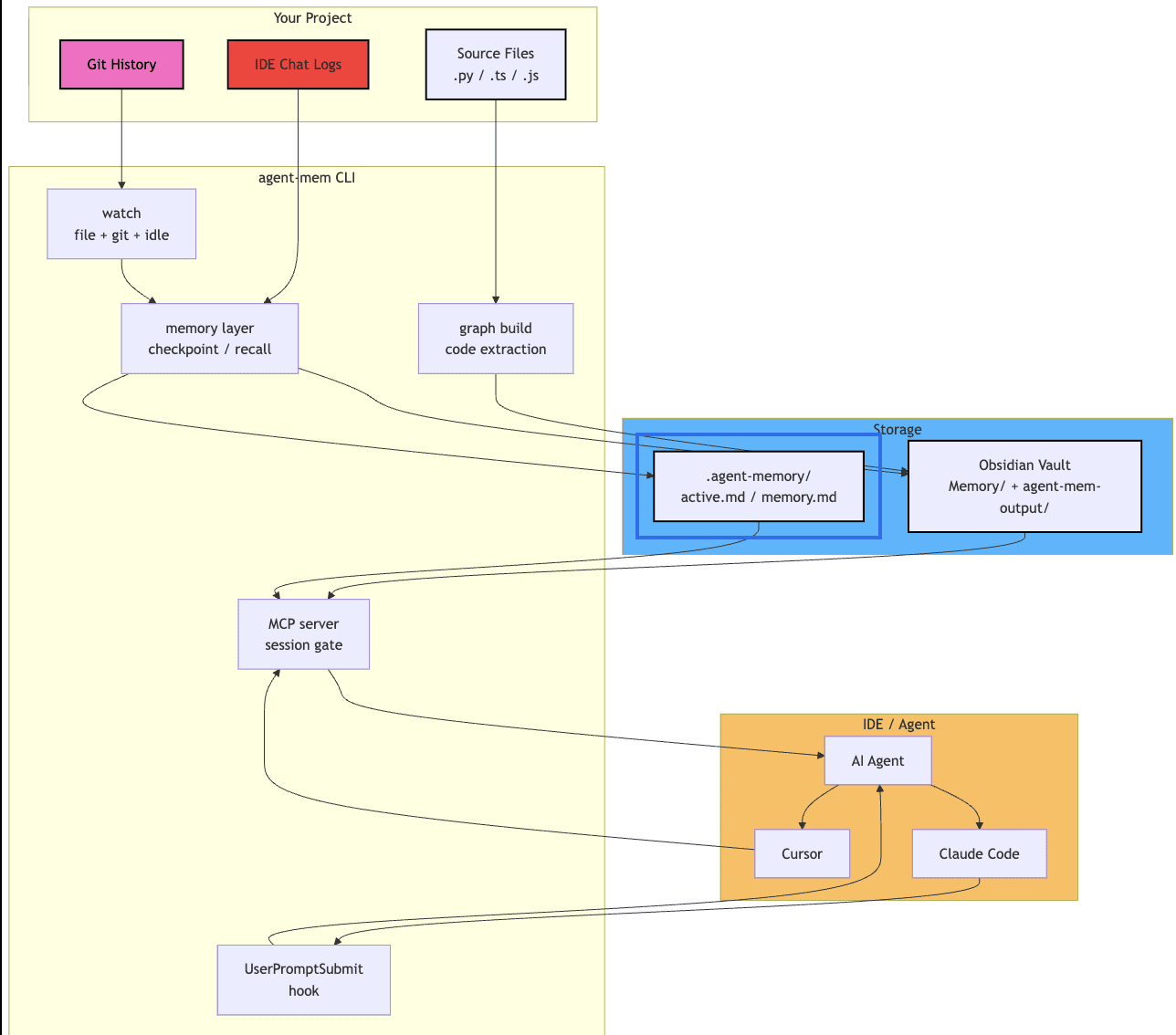
What agent-mem actually is
A CLI tool that watches your project, extracts structure from the code, captures decisions and blockers from your sessions, and writes everything as Obsidian-compatible markdown notes. When you start a new chat, the agent loads those notes instead of starting from scratch.
pip install easy-agent-mem agent-mem init agent-mem watch
That's the whole onboarding. init sets up storage and IDE hooks. watch runs in the background and generates handoff prompts when you switch chats.
It runs locally. It writes markdown. It hooks into Kiro, Cursor, Claude Code, and VS Code automatically. There's no server, no account, no telemetry.
I'll get to why this is harder than it sounds.
The three layers
I ended up splitting the system into three layers because trying to do everything in one pipeline was making the code unreadable.
Code understanding layer
This is the part that reads your project. Python files go through Python's ast module. TypeScript and JavaScript go through tree-sitter, the same parser Cursor uses, lazy-loaded as an optional extra so people who only write Python don't pay the install cost.
What it extracts: classes, functions, imports, decorators, docstrings, and tagged comments like # TODO or # NOTE. Then it does one thing most code-memory tools skip: a call graph.
Concept: Call graph
A directed graph where each node is a function and each edge is "function A calls function B." Build one across files and you can answer questions like "what depends on this?" or "what's the blast radius of changing this?"
Why it matters here: when an agent asks "where is this function used?", a call graph beats grep because grep matches text and a call graph matches semantics.
The first version was per-file only. Function A calls function B in the same file, fine! Function A in auth.py calls function B in db.py - invisible. I fixed that with a post-parse resolution pass: parse everything first, build a global name-to-file map, then walk every recorded call and resolve the file. Two-pass instead of single-pass. Slightly more memory, dramatically more useful.
Memory layer
This is where extracted signal becomes durable notes. Two storage modes: Obsidian (if you have a vault configured) and a .agent-memory/ fallback folder. Same markdown either way.
The output is structured: Code/, Decisions/, Sessions/, an Index.md dashboard. Wikilinks everywhere so Obsidian's graph view actually shows the project as a graph.

I argued with myself for a while about whether to use embeddings here. I didn't. Not yet. The deterministic markdown layer has to be solid before semantic search makes sense, and I wanted to ship something I could benchmark.
Enforcement layer
This is the layer I'm proudest of and the one that took the longest to get right.
Here's the dirty secret of every "memory for AI agents" tool: the agent has to actually use the memory. You can build the cleanest persistence layer in the world and the agent will cheerfully ignore it because nothing in its loop forces a read.
I tried being polite first. Wrote a CLAUDE.md and a .cursorrules file telling the agent to call query_memory at session start. Worked maybe forty percent of the time. The rest of the time the agent would summarize a session having loaded zero context, hallucinate "decisions" that contradicted my actual notes, and apologize when corrected. Apologies are not memory.
Two-layer fix:
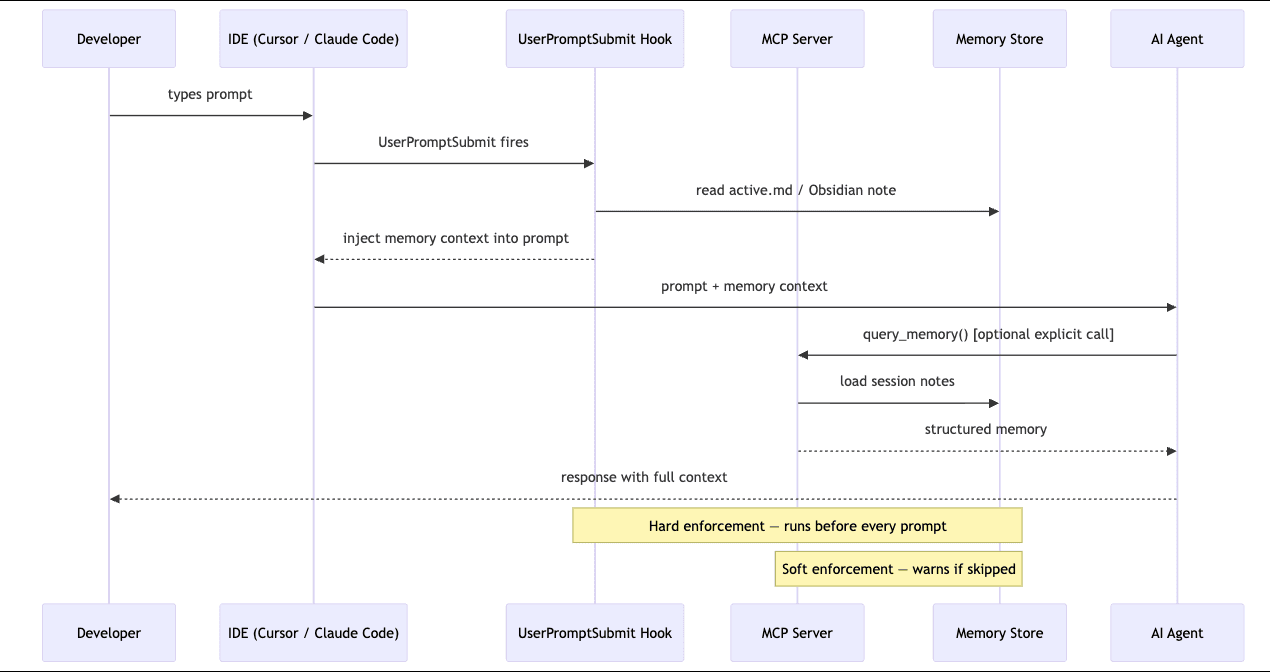
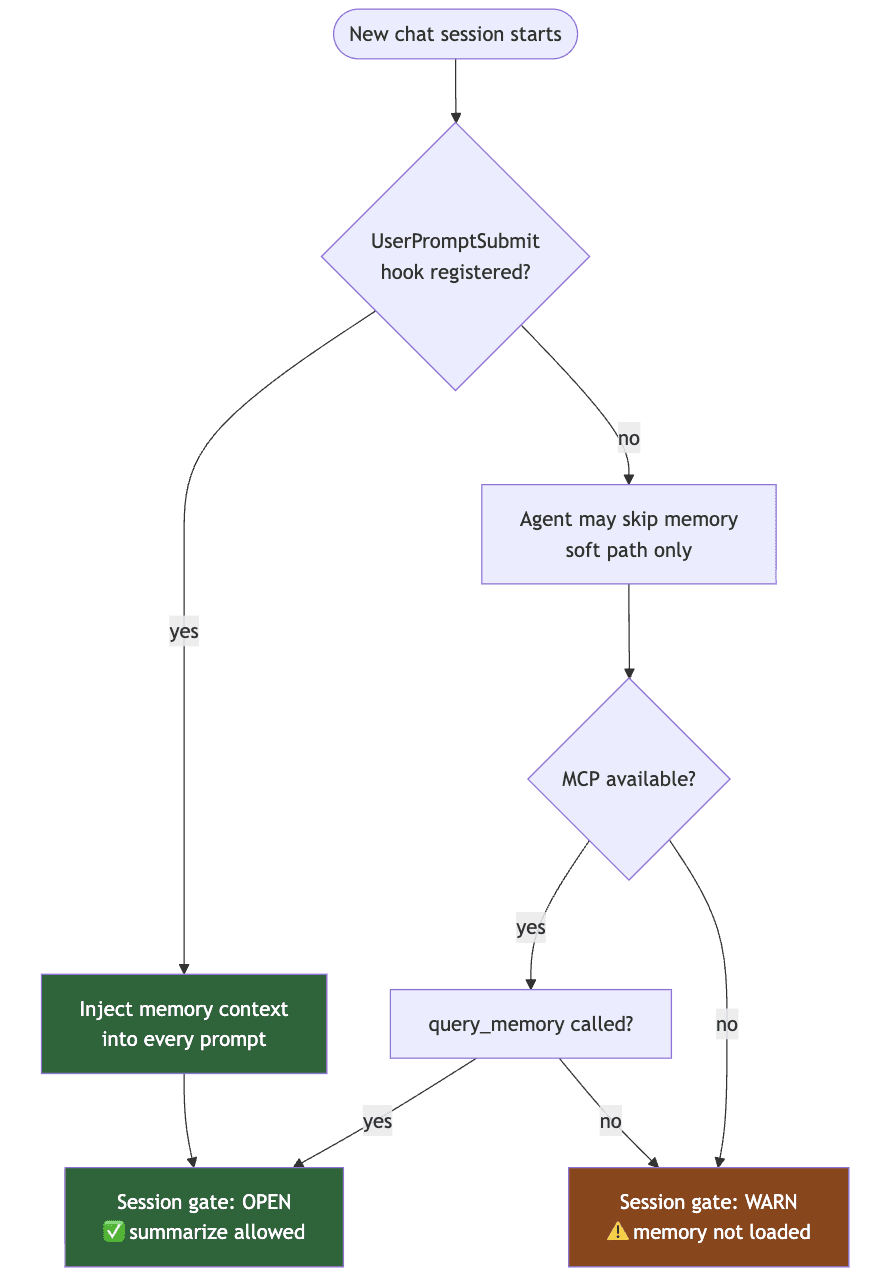
MCP session gate. The MCP server tracks whether query_memory was called this session. If you try to call summarize_to_obsidian without loading memory first, the response prepends a hard warning. Soft enforcement — the agent can still proceed, but it gets told.
Claude Code UserPromptSubmit hook. This one's the hammer. Claude Code lets you register a shell script that runs before every user prompt is sent to the model. The script reads the latest memory artifact and injects it into the prompt. The agent literally cannot answer without seeing memory first.
{ "hooks": { "UserPromptSubmit": [ { "matcher": "", "hooks": [{ "type": "command", "command": "..." }] } ] } }
That matcher: "" was the bug that ate two hours. The format is nested: an array of matcher objects, each containing an array of hooks. I had it flat. The hook silently never ran. No error, no warning. Just a quietly broken enforcement layer for a week. Lesson: when something silently does nothing, doubt the schema before you doubt the logic.
The hard parts
The blog version of building a tool always sounds linear. The real version is mostly debugging your assumptions.
Agents ignoring instructions. Already covered. The fix wasn't a better prompt, it was moving enforcement out of the prompt entirely and into the harness.
No way to measure detection quality. I caught myself eyeballing whether the extractor "looked right" on real code. That's not a methodology. So I added agent-mem graph benchmark , a fixture-based precision/recall/F1 harness. Synthetic Python and TypeScript files with hand-labeled ground truth (classes, functions, imports, comments, calls). Run the extractor, compare, score.
$ agent-mem graph benchmark Python : TP=22 FP=0 FN=0 P=1.00 R=1.00 F1=1.00 TypeScript: TP=9 FP=0 FN=0 P=1.00 R=1.00 F1=1.00
The 1.00 looks great. It also lies. The fixtures are synthetic : small, clean, and written by me. Real codebases have decorators, dynamic imports, monkey-patches, and code that breaks AST parsers in creative ways. The benchmark proves the extractor doesn't regress on known patterns. It doesn't prove it generalizes. But then, I'd rather have a synthetic 1.00 with a clear honest caveat than a real-world 0.83 nobody can reproduce.
Concept: Precision, recall, F1
Precision: of the things you flagged, how many were right. Recall: of the things that existed, how many you caught. F1: harmonic mean of the two penalizes you for being lopsided.
Why it matters here: a code extractor that finds 90% of functions but invents fake ones is worse than one that finds 70% and never lies.
Multi-language support arrived late. First version was Python-only. Then I tried it on a TypeScript project and the extractor was useless. Added tree-sitter as an optional extra (pip install 'easy-agent-mem[multilang]') so the base install stays small. Tree-sitter ships precompiled grammars for TS, TSX, JS. Drop them in, walk the tree, extract the same shape of records.
Concept: Tree-sitter
A parser generator and incremental parsing library. Give it a grammar for a language and it produces a parser that can re-parse on every keystroke without re-reading the whole file.
Why it matters here: regex on source code lies to you. Tree-sitter doesn't. Cursor uses it. So do I.
MCP server stability - is the standard for tools-to-LLM communication. It's young. Spec changes break things. I had a session where the server would start, accept the first call, then return malformed responses on the second. The fix wasn't profound (transport reset) but tracking it down meant reading SDK source on a Saturday.
(This one needs a lot of working).
Compared to what's out there
System | Focus | Code-aware | IDE Enforcement | Call Graph | Multi-language | Local-first | Benchmarked |
|---|---|---|---|---|---|---|---|
agent-mem | Code session memory | ✅ | ✅ MCP gate + hooks | ✅ | ✅ Python, TS, JS | ✅ | ✅ P/R/F1 |
mem0 | NLP conversation memory | ❌ | ❌ | ❌ | ❌ | Partial | ✅ NLP tasks |
Zep | Conversation memory | ❌ | ❌ | ❌ | ❌ | ❌ | Limited |
MemGPT / Letta | General memory management | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ NLP tasks |
Continue.dev | IDE context window | Partial | ❌ | ❌ | Partial | ✅ | ❌ |
Aider | Context management | Partial | ❌ | ❌ | Partial | ✅ | ❌ |
mem0 is solid for conversational memory but doesn't know what a function is. It's optimized for chatbot personalization, not code.
Zep is similar, a temporal knowledge graphs over conversation. Great for support agents. Not built around code structure.
MemGPT / Letta is a general memory management framework. Powerful but heavy, and again — no code awareness, no IDE enforcement.
The thing none of them do is enforce usage. They give you APIs. They trust you to call them. agent-mem assumes the agent is going to skip the call if it can, so the harness makes skipping impossible.
What's actually different
Three things, plainly:
Memory you can't skip. MCP gate plus Claude Code hook. The agent reads memory or it doesn't reply.
Code understanding, not chat logs. Tree-sitter and AST. Real call graphs across files. Real classes, real imports.
A benchmark that exists. Synthetic for now, but it exists, it's reproducible, and it runs on every change.
Everything else is plumbing.
What I'm less certain about is the long-term compaction problem. Right now the memory grows and the agent reads it. At some point the memory itself becomes too long to be useful, and you need semantic search, not grep. That's the next hard problem. I have thoughts, not code.
Do give it a star on GitHub. Try it out and let me know your honest feedback too!
I know, I'm late to the party but refining an building it to a phase where it actually matters, took some time.
GitHub: atharvavdeo/agent-mem
PyPI: easy-agent-mem
Every day, the same scene played out - Open VS/Claude/Cursor, Paste the same context I'd already pasted yesterday. Watch the agent confidently propose a refactor that contradicts a decision I made three sessions ago. If not, then waste tokens just making it understand the code.
A the time of the idea of solving this problem - I did not know of the existence of tools like mem0, let alone graphify. Ok, back to the main thing.
If you've shipped anything non-trivial with an AI coding agent, you know the loop. The model is brilliant for thirty messages and then the context window fills up, the session ends, and you're back to square one : re-explaining the architecture, re-listing the decisions, re-pasting the file tree. The agent has no memory. Worse, it pretends to but ends up eating tokens like kids on a birthday bash.
This post is about what I did about it. The tool is called agent-mem. It's a CLI-first persistent memory system for AI coding sessions. You can pip install easy-agent-mem it right now. But as much as I want to talk about the tool, more about the wall I kept running into, and how three unrelated ideas from Cursor, Karpathy, and Obsidian - ended up shaping the design.
Three things I stole
I didn't invent any of this. I stitched together three insights that had been floating in my head for days.
Cursor's structural parsing. Cursor doesn't grep your code. It runs it through tree-sitter and builds a real syntax tree, then indexes that tree. The reason Cursor's autocomplete feels different from a regex-based plugin is because it actually understands class Foo extends Bar as a class declaration with a parent, not as a string of characters that happens to contain the word "extends." That's the bar. Anything less is search dressed up as understanding.
Why it matters: if your "memory" system is just storing chat transcripts, it's a chat log with extra steps. Code memory has to know what a function is.
Our college's Operating System's lecture on RAM vs disk framing. Even Andrej said something offhand in a talk that I keep coming back to: an LLM's context window is RAM. Fast, expensive, volatile. Persistent memory has to live somewhere else - on disk, structured, addressable. You don't shove your entire hard drive into RAM at boot. You page in what you need. Not to mention his post on LLM-Wikis that blew up : Read it here.
Obsidian's local-first approach. Obsidian stores your notes as plain markdown files in a folder you own. No cloud. No lock-in. Wikilinks like [[some-note]] form a graph automatically. Open the folder in any text editor and it still works.
Why it matters: developers do not want their codebase memory living in someone else's database. We already have a vault - it's called the project directory. So, Use it!
Three different directions, one obvious synthesis: parse the code structurally (Cursor), persist the parsed signal as markdown (Obsidian), and treat that markdown as the disk layer the agent pages from (Karpathy).
What agent-mem actually is
A CLI tool that watches your project, extracts structure from the code, captures decisions and blockers from your sessions, and writes everything as Obsidian-compatible markdown notes. When you start a new chat, the agent loads those notes instead of starting from scratch.
pip install easy-agent-mem agent-mem init agent-mem watch
That's the whole onboarding. init sets up storage and IDE hooks. watch runs in the background and generates handoff prompts when you switch chats.
It runs locally. It writes markdown. It hooks into Kiro, Cursor, Claude Code, and VS Code automatically. There's no server, no account, no telemetry.
I'll get to why this is harder than it sounds.
The three layers
I ended up splitting the system into three layers because trying to do everything in one pipeline was making the code unreadable.
Code understanding layer
This is the part that reads your project. Python files go through Python's ast module. TypeScript and JavaScript go through tree-sitter, the same parser Cursor uses, lazy-loaded as an optional extra so people who only write Python don't pay the install cost.
What it extracts: classes, functions, imports, decorators, docstrings, and tagged comments like # TODO or # NOTE. Then it does one thing most code-memory tools skip: a call graph.
Concept: Call graph
A directed graph where each node is a function and each edge is "function A calls function B." Build one across files and you can answer questions like "what depends on this?" or "what's the blast radius of changing this?"
Why it matters here: when an agent asks "where is this function used?", a call graph beats grep because grep matches text and a call graph matches semantics.
The first version was per-file only. Function A calls function B in the same file, fine! Function A in auth.py calls function B in db.py - invisible. I fixed that with a post-parse resolution pass: parse everything first, build a global name-to-file map, then walk every recorded call and resolve the file. Two-pass instead of single-pass. Slightly more memory, dramatically more useful.
Memory layer
This is where extracted signal becomes durable notes. Two storage modes: Obsidian (if you have a vault configured) and a .agent-memory/ fallback folder. Same markdown either way.
The output is structured: Code/, Decisions/, Sessions/, an Index.md dashboard. Wikilinks everywhere so Obsidian's graph view actually shows the project as a graph.
I argued with myself for a while about whether to use embeddings here. I didn't. Not yet. The deterministic markdown layer has to be solid before semantic search makes sense, and I wanted to ship something I could benchmark.
Enforcement layer
This is the layer I'm proudest of and the one that took the longest to get right.
Here's the dirty secret of every "memory for AI agents" tool: the agent has to actually use the memory. You can build the cleanest persistence layer in the world and the agent will cheerfully ignore it because nothing in its loop forces a read.
I tried being polite first. Wrote a CLAUDE.md and a .cursorrules file telling the agent to call query_memory at session start. Worked maybe forty percent of the time. The rest of the time the agent would summarize a session having loaded zero context, hallucinate "decisions" that contradicted my actual notes, and apologize when corrected. Apologies are not memory.
Two-layer fix:
MCP session gate. The MCP server tracks whether query_memory was called this session. If you try to call summarize_to_obsidian without loading memory first, the response prepends a hard warning. Soft enforcement — the agent can still proceed, but it gets told.
Claude Code UserPromptSubmit hook. This one's the hammer. Claude Code lets you register a shell script that runs before every user prompt is sent to the model. The script reads the latest memory artifact and injects it into the prompt. The agent literally cannot answer without seeing memory first.
{ "hooks": { "UserPromptSubmit": [ { "matcher": "", "hooks": [{ "type": "command", "command": "..." }] } ] } }
That matcher: "" was the bug that ate two hours. The format is nested: an array of matcher objects, each containing an array of hooks. I had it flat. The hook silently never ran. No error, no warning. Just a quietly broken enforcement layer for a week. Lesson: when something silently does nothing, doubt the schema before you doubt the logic.
The hard parts
The blog version of building a tool always sounds linear. The real version is mostly debugging your assumptions.
Agents ignoring instructions. Already covered. The fix wasn't a better prompt, it was moving enforcement out of the prompt entirely and into the harness.
No way to measure detection quality. I caught myself eyeballing whether the extractor "looked right" on real code. That's not a methodology. So I added agent-mem graph benchmark , a fixture-based precision/recall/F1 harness. Synthetic Python and TypeScript files with hand-labeled ground truth (classes, functions, imports, comments, calls). Run the extractor, compare, score.
$ agent-mem graph benchmark Python : TP=22 FP=0 FN=0 P=1.00 R=1.00 F1=1.00 TypeScript: TP=9 FP=0 FN=0 P=1.00 R=1.00 F1=1.00
The 1.00 looks great. It also lies. The fixtures are synthetic : small, clean, and written by me. Real codebases have decorators, dynamic imports, monkey-patches, and code that breaks AST parsers in creative ways. The benchmark proves the extractor doesn't regress on known patterns. It doesn't prove it generalizes. But then, I'd rather have a synthetic 1.00 with a clear honest caveat than a real-world 0.83 nobody can reproduce.
Concept: Precision, recall, F1
Precision: of the things you flagged, how many were right. Recall: of the things that existed, how many you caught. F1: harmonic mean of the two penalizes you for being lopsided.
Why it matters here: a code extractor that finds 90% of functions but invents fake ones is worse than one that finds 70% and never lies.
Multi-language support arrived late. First version was Python-only. Then I tried it on a TypeScript project and the extractor was useless. Added tree-sitter as an optional extra (pip install 'easy-agent-mem[multilang]') so the base install stays small. Tree-sitter ships precompiled grammars for TS, TSX, JS. Drop them in, walk the tree, extract the same shape of records.
Concept: Tree-sitter
A parser generator and incremental parsing library. Give it a grammar for a language and it produces a parser that can re-parse on every keystroke without re-reading the whole file.
Why it matters here: regex on source code lies to you. Tree-sitter doesn't. Cursor uses it. So do I.
MCP server stability - is the standard for tools-to-LLM communication. It's young. Spec changes break things. I had a session where the server would start, accept the first call, then return malformed responses on the second. The fix wasn't profound (transport reset) but tracking it down meant reading SDK source on a Saturday.
(This one needs a lot of working).
Compared to what's out there
System | Focus | Code-aware | IDE Enforcement | Call Graph | Multi-language | Local-first | Benchmarked |
|---|---|---|---|---|---|---|---|
agent-mem | Code session memory | ✅ | ✅ MCP gate + hooks | ✅ | ✅ Python, TS, JS | ✅ | ✅ P/R/F1 |
mem0 | NLP conversation memory | ❌ | ❌ | ❌ | ❌ | Partial | ✅ NLP tasks |
Zep | Conversation memory | ❌ | ❌ | ❌ | ❌ | ❌ | Limited |
MemGPT / Letta | General memory management | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ NLP tasks |
Continue.dev | IDE context window | Partial | ❌ | ❌ | Partial | ✅ | ❌ |
Aider | Context management | Partial | ❌ | ❌ | Partial | ✅ | ❌ |
mem0 is solid for conversational memory but doesn't know what a function is. It's optimized for chatbot personalization, not code.
Zep is similar, a temporal knowledge graphs over conversation. Great for support agents. Not built around code structure.
MemGPT / Letta is a general memory management framework. Powerful but heavy, and again — no code awareness, no IDE enforcement.
The thing none of them do is enforce usage. They give you APIs. They trust you to call them. agent-mem assumes the agent is going to skip the call if it can, so the harness makes skipping impossible.
What's actually different
Three things, plainly:
Memory you can't skip. MCP gate plus Claude Code hook. The agent reads memory or it doesn't reply.
Code understanding, not chat logs. Tree-sitter and AST. Real call graphs across files. Real classes, real imports.
A benchmark that exists. Synthetic for now, but it exists, it's reproducible, and it runs on every change.
Everything else is plumbing.
What I'm less certain about is the long-term compaction problem. Right now the memory grows and the agent reads it. At some point the memory itself becomes too long to be useful, and you need semantic search, not grep. That's the next hard problem. I have thoughts, not code.
Do give it a star on GitHub. Try it out and let me know your honest feedback too!
I know, I'm late to the party but refining an building it to a phase where it actually matters, took some time.
GitHub: atharvavdeo/agent-mem
PyPI: easy-agent-mem
Every day, the same scene played out - Open VS/Claude/Cursor, Paste the same context I'd already pasted yesterday. Watch the agent confidently propose a refactor that contradicts a decision I made three sessions ago. If not, then waste tokens just making it understand the code.
A the time of the idea of solving this problem - I did not know of the existence of tools like mem0, let alone graphify. Ok, back to the main thing.
If you've shipped anything non-trivial with an AI coding agent, you know the loop. The model is brilliant for thirty messages and then the context window fills up, the session ends, and you're back to square one : re-explaining the architecture, re-listing the decisions, re-pasting the file tree. The agent has no memory. Worse, it pretends to but ends up eating tokens like kids on a birthday bash.
This post is about what I did about it. The tool is called agent-mem. It's a CLI-first persistent memory system for AI coding sessions. You can pip install easy-agent-mem it right now. But as much as I want to talk about the tool, more about the wall I kept running into, and how three unrelated ideas from Cursor, Karpathy, and Obsidian - ended up shaping the design.
Three things I stole
I didn't invent any of this. I stitched together three insights that had been floating in my head for days.
Cursor's structural parsing. Cursor doesn't grep your code. It runs it through tree-sitter and builds a real syntax tree, then indexes that tree. The reason Cursor's autocomplete feels different from a regex-based plugin is because it actually understands class Foo extends Bar as a class declaration with a parent, not as a string of characters that happens to contain the word "extends." That's the bar. Anything less is search dressed up as understanding.
Why it matters: if your "memory" system is just storing chat transcripts, it's a chat log with extra steps. Code memory has to know what a function is.
Our college's Operating System's lecture on RAM vs disk framing. Even Andrej said something offhand in a talk that I keep coming back to: an LLM's context window is RAM. Fast, expensive, volatile. Persistent memory has to live somewhere else - on disk, structured, addressable. You don't shove your entire hard drive into RAM at boot. You page in what you need. Not to mention his post on LLM-Wikis that blew up : Read it here.
Obsidian's local-first approach. Obsidian stores your notes as plain markdown files in a folder you own. No cloud. No lock-in. Wikilinks like [[some-note]] form a graph automatically. Open the folder in any text editor and it still works.
Why it matters: developers do not want their codebase memory living in someone else's database. We already have a vault - it's called the project directory. So, Use it!
Three different directions, one obvious synthesis: parse the code structurally (Cursor), persist the parsed signal as markdown (Obsidian), and treat that markdown as the disk layer the agent pages from (Karpathy).
What agent-mem actually is
A CLI tool that watches your project, extracts structure from the code, captures decisions and blockers from your sessions, and writes everything as Obsidian-compatible markdown notes. When you start a new chat, the agent loads those notes instead of starting from scratch.
pip install easy-agent-mem agent-mem init agent-mem watch
That's the whole onboarding. init sets up storage and IDE hooks. watch runs in the background and generates handoff prompts when you switch chats.
It runs locally. It writes markdown. It hooks into Kiro, Cursor, Claude Code, and VS Code automatically. There's no server, no account, no telemetry.
I'll get to why this is harder than it sounds.
The three layers
I ended up splitting the system into three layers because trying to do everything in one pipeline was making the code unreadable.
Code understanding layer
This is the part that reads your project. Python files go through Python's ast module. TypeScript and JavaScript go through tree-sitter, the same parser Cursor uses, lazy-loaded as an optional extra so people who only write Python don't pay the install cost.
What it extracts: classes, functions, imports, decorators, docstrings, and tagged comments like # TODO or # NOTE. Then it does one thing most code-memory tools skip: a call graph.
Concept: Call graph
A directed graph where each node is a function and each edge is "function A calls function B." Build one across files and you can answer questions like "what depends on this?" or "what's the blast radius of changing this?"
Why it matters here: when an agent asks "where is this function used?", a call graph beats grep because grep matches text and a call graph matches semantics.
The first version was per-file only. Function A calls function B in the same file, fine! Function A in auth.py calls function B in db.py - invisible. I fixed that with a post-parse resolution pass: parse everything first, build a global name-to-file map, then walk every recorded call and resolve the file. Two-pass instead of single-pass. Slightly more memory, dramatically more useful.
Memory layer
This is where extracted signal becomes durable notes. Two storage modes: Obsidian (if you have a vault configured) and a .agent-memory/ fallback folder. Same markdown either way.
The output is structured: Code/, Decisions/, Sessions/, an Index.md dashboard. Wikilinks everywhere so Obsidian's graph view actually shows the project as a graph.
I argued with myself for a while about whether to use embeddings here. I didn't. Not yet. The deterministic markdown layer has to be solid before semantic search makes sense, and I wanted to ship something I could benchmark.
Enforcement layer
This is the layer I'm proudest of and the one that took the longest to get right.
Here's the dirty secret of every "memory for AI agents" tool: the agent has to actually use the memory. You can build the cleanest persistence layer in the world and the agent will cheerfully ignore it because nothing in its loop forces a read.
I tried being polite first. Wrote a CLAUDE.md and a .cursorrules file telling the agent to call query_memory at session start. Worked maybe forty percent of the time. The rest of the time the agent would summarize a session having loaded zero context, hallucinate "decisions" that contradicted my actual notes, and apologize when corrected. Apologies are not memory.
Two-layer fix:
MCP session gate. The MCP server tracks whether query_memory was called this session. If you try to call summarize_to_obsidian without loading memory first, the response prepends a hard warning. Soft enforcement — the agent can still proceed, but it gets told.
Claude Code UserPromptSubmit hook. This one's the hammer. Claude Code lets you register a shell script that runs before every user prompt is sent to the model. The script reads the latest memory artifact and injects it into the prompt. The agent literally cannot answer without seeing memory first.
{ "hooks": { "UserPromptSubmit": [ { "matcher": "", "hooks": [{ "type": "command", "command": "..." }] } ] } }
That matcher: "" was the bug that ate two hours. The format is nested: an array of matcher objects, each containing an array of hooks. I had it flat. The hook silently never ran. No error, no warning. Just a quietly broken enforcement layer for a week. Lesson: when something silently does nothing, doubt the schema before you doubt the logic.
The hard parts
The blog version of building a tool always sounds linear. The real version is mostly debugging your assumptions.
Agents ignoring instructions. Already covered. The fix wasn't a better prompt, it was moving enforcement out of the prompt entirely and into the harness.
No way to measure detection quality. I caught myself eyeballing whether the extractor "looked right" on real code. That's not a methodology. So I added agent-mem graph benchmark , a fixture-based precision/recall/F1 harness. Synthetic Python and TypeScript files with hand-labeled ground truth (classes, functions, imports, comments, calls). Run the extractor, compare, score.
$ agent-mem graph benchmark Python : TP=22 FP=0 FN=0 P=1.00 R=1.00 F1=1.00 TypeScript: TP=9 FP=0 FN=0 P=1.00 R=1.00 F1=1.00
The 1.00 looks great. It also lies. The fixtures are synthetic : small, clean, and written by me. Real codebases have decorators, dynamic imports, monkey-patches, and code that breaks AST parsers in creative ways. The benchmark proves the extractor doesn't regress on known patterns. It doesn't prove it generalizes. But then, I'd rather have a synthetic 1.00 with a clear honest caveat than a real-world 0.83 nobody can reproduce.
Concept: Precision, recall, F1
Precision: of the things you flagged, how many were right. Recall: of the things that existed, how many you caught. F1: harmonic mean of the two penalizes you for being lopsided.
Why it matters here: a code extractor that finds 90% of functions but invents fake ones is worse than one that finds 70% and never lies.
Multi-language support arrived late. First version was Python-only. Then I tried it on a TypeScript project and the extractor was useless. Added tree-sitter as an optional extra (pip install 'easy-agent-mem[multilang]') so the base install stays small. Tree-sitter ships precompiled grammars for TS, TSX, JS. Drop them in, walk the tree, extract the same shape of records.
Concept: Tree-sitter
A parser generator and incremental parsing library. Give it a grammar for a language and it produces a parser that can re-parse on every keystroke without re-reading the whole file.
Why it matters here: regex on source code lies to you. Tree-sitter doesn't. Cursor uses it. So do I.
MCP server stability - is the standard for tools-to-LLM communication. It's young. Spec changes break things. I had a session where the server would start, accept the first call, then return malformed responses on the second. The fix wasn't profound (transport reset) but tracking it down meant reading SDK source on a Saturday.
(This one needs a lot of working).
Compared to what's out there
System | Focus | Code-aware | IDE Enforcement | Call Graph | Multi-language | Local-first | Benchmarked |
|---|---|---|---|---|---|---|---|
agent-mem | Code session memory | ✅ | ✅ MCP gate + hooks | ✅ | ✅ Python, TS, JS | ✅ | ✅ P/R/F1 |
mem0 | NLP conversation memory | ❌ | ❌ | ❌ | ❌ | Partial | ✅ NLP tasks |
Zep | Conversation memory | ❌ | ❌ | ❌ | ❌ | ❌ | Limited |
MemGPT / Letta | General memory management | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ NLP tasks |
Continue.dev | IDE context window | Partial | ❌ | ❌ | Partial | ✅ | ❌ |
Aider | Context management | Partial | ❌ | ❌ | Partial | ✅ | ❌ |
mem0 is solid for conversational memory but doesn't know what a function is. It's optimized for chatbot personalization, not code.
Zep is similar, a temporal knowledge graphs over conversation. Great for support agents. Not built around code structure.
MemGPT / Letta is a general memory management framework. Powerful but heavy, and again — no code awareness, no IDE enforcement.
The thing none of them do is enforce usage. They give you APIs. They trust you to call them. agent-mem assumes the agent is going to skip the call if it can, so the harness makes skipping impossible.
What's actually different
Three things, plainly:
Memory you can't skip. MCP gate plus Claude Code hook. The agent reads memory or it doesn't reply.
Code understanding, not chat logs. Tree-sitter and AST. Real call graphs across files. Real classes, real imports.
A benchmark that exists. Synthetic for now, but it exists, it's reproducible, and it runs on every change.
Everything else is plumbing.
What I'm less certain about is the long-term compaction problem. Right now the memory grows and the agent reads it. At some point the memory itself becomes too long to be useful, and you need semantic search, not grep. That's the next hard problem. I have thoughts, not code.
Do give it a star on GitHub. Try it out and let me know your honest feedback too!
Be the first to know about every new letter.
No spam, unsubscribe anytime.